

What is a canonical URL?
Each and every page of your website should have a canonical URL. This is defined by adding the tag <link rel=”canonical” href=”yourpageurl”>, in the <head> of your posts and pages.
It’s a simple way to tell Google which version of a page to take into account when indexing your website. The concept is similar to the preferred domain where a single page is accessible through various URLs.
A canonical URL is added in the HEAD section of a page and tells search engine which is the preferred URL for the particular page. A canonical URL can point to itself (self-referencing) or to a different URL.
What is Canonical Tag?
A canonical tag (aka rel=”canonical”) is a way of telling search engines that a specific URL represents the master copy of a page. Using the canonical tag prevents problems caused by identical or “duplicate” content appearing on multiple URLs. Practically speaking, the canonical tag tells search engines which version of a URL you want to appear in search results.
Canonical Tags are most commonly used to:
- Help webmasters solve duplicate content issues
- Help search engines index the most appropriate page (in case pages have similar/identical content)
- Help webmasters specify their preferred domain
- It’s a way to specify which page to index in cases where you have accelerated mobile pages (AMP) enabled on your site
How do I find my canonical URL?
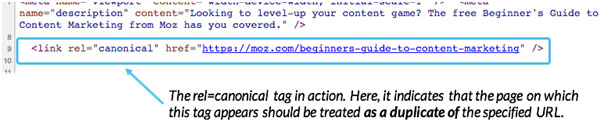
A canonical URL is only visible to search engine crawlers and not users. It is added to the <HEAD></HEAD> section of a page and has the following format:
Code Sample
<link rel=”canonical” href=”CANONICAL-URL”/>
To find the canonical URL of page, you can view the HTML Source of a page.
When and How to use Canonical URLs?
Duplicate content is a complicated subject, but when search engines crawl many URLs with identical (or very similar) content, it can cause a number of SEO problems.
- First, if search crawlers have to wade through too much duplicate content, they may miss some of your unique content.
- Second, large-scale duplication may dilute your ranking ability.
- Finally, even if your content does rank, search engines may pick the wrong URL as the “original.”
A website is more likely to have duplicate content issues, even if you don’t intentionally duplicate your content across different URLs.
Typical cases of duplicate content include:
- A URL is accessible with or without www in the URL – For example:
http://themonkeyowl.com/post-title and
http://www.themonkeyowl.com/post-title
- A URL is accessible with both http and https protocols – For example:
https://themonkeyowl.com/post-title and
http://themonkeyowl.com/post-title
- Pages that have print friendly versions – For example:
https://www.themonkeyowl.com/post-title/ and
https://themonkeyowl.com/post-title/?print=true
- Pages with identical content but different URLs – For example:
https://www.themonkeyowl.com/courses/SEO-Course and
https://www.themonkeyowl.com/seo-course
As humans, tend to think of a page as a concept, such as your homepage. For search engines, though, every unique URL is a separate page.
For example, search crawlers might be able to reach your homepage in all of the following ways:
- http://www.example.com
- https://www.example.com
- http://example.com
- http://example.com/index.php
- http://example.com/home
To a human, all of these URLs represent a single page. To a search crawler, though, every single one of these URLs is a unique “page.”

























Add comment